暂时还没想好摘要
周记批改问题:
国内外舆情处理方式可有不同?
这个问题我找到了一篇写的比较详细的文章:【[1]周松青.中美网络舆情监控比较[J].北京社会科学,2017(01):22-32.DOI:10.13262/j.bjsshkxy.bjshkx.170103.】北核和CSSCI的论文。
定义辨析
二者的核心差异:中国的监控主体随时监测网络状态,跟踪网络热点事件,防止演化为网络群体性事件或其他重大事件,监控的重心是网络及其表达;美国的监控主体将网络作为一个工具和媒介,监控网络中活动的人,并充分利用网络技术监控和寻找危险的人,其监控的重心是危险的人和行为,网络只是方便使用、成本低廉的技术工具。
两国监控授权和限制
(1)中美网络舆情监控授权和限制的方向不同。
在法理上美国没有限制个体和企业在网络中的行为和表达,这是宪法中的言论自由和出版自由所约定的;中国则对网络表达作了比较详细的规定,提出了网络表达的禁止性条款,如果出现这些表达会受到惩罚
(2)美国网络舆情监控以执法、情报机构的侵入性为特征,受到隐私权的限制。
美国最高法院在公民的隐私权和执法机构的执法权间寻求平衡,不断摇摆。中国的网络舆情监控在法律上的授权没有遇到阻碍,执法机构可以管控网络行为和内容表达,立足于阻止不适当的网络内容传播。
两国监控类型比较
立足点的差异:美国将所有能触及到的主体都纳入监控范围,建立大范围的数字档案,而中国则只针对个案进行监控
策略的差异:美国执法和情报部门采取进攻态势,深挖各种网络信息建立详尽的档案。中国监控采取防堵策略,阻止敏感信息扩散造成社会不稳定,以阻止扩散为核心,立足于维稳。
深度和广度存在差异:美国情报部门全面监控互联网,而中国舆情监控以已经发生的信息为监控对象,并以国家安全和社会稳定的标准来评判信息。
监控主体的差异:美国监控体系以情报机构、安全机构、国防机构为主体,且机构之间有完整的整合机制,但中国的网络舆情监控机构遍地开花,各级别政府、企事业单位及部分私营公司的舆情监控部门相互隔离,互不统属,且自扫门前雪,各部门之间没有形成有效的联络通道。
另外:
这篇文章写到了我一直困惑的点,在下面文献二的另外中提到的,为什么即使用英文搜索还是搜到的都是中国学者写的文章:网络舆情是一个具有中国特色的概念,一种是翻译为网络公共情感(Internet public feeling,the network public sentiment,network popular feelings),一种是翻译为网络公共观点(Online public opinions,Network public opinion),或者使用monitor这类监控的词汇,这些概念都将网络拟人化了,认为网络能够产生情绪和观点,而西方学者更多使用的是Surveillance,这个监控涵盖的面更广,涉及宏观和微观,西方学者不把网络拟人化,而是将其作为工具,监控的主语是政府、特工、警察、企业等。网络是用户的工具,更是监控者用于监控用户的工具。
高校在舆情事件中的应对方法可有不同?
找到一篇【崔彦琨,蒋建华.高校舆情治理碎片化:表现、归因及破解之道[J].黑龙江高教研究,2021,39(10):6-12.DOI:10.19903/j.cnki.cn23-1074/g.2021.10.002.】
这一个话题我是搜的“高校舆情”OR“高校舆论”的模糊主题,时间限定在了2017年以来,虽然也有几十篇文章,但是大多都是简单的叙述性的,这一篇讲的还比较的深入一点。
问题提出:
高校作为相对开放的社会系统,十分受外部环境变化所影响,并且也依赖外部环境。当舆情发生时,高校要对内外负责,舆情处理不当会损害学校形象,同时学校形象也是学校软实力的一部分。有学者认为高校舆情治理存在着像粗放管理、被动管理、观念落后、组织落后等问题,而作者则从“整体性治理理论”出发,阐释了高校舆情治理碎片化现状的原因以及建议
碎片化问题审视:
治理理念碎片化:目前,高校舆情治理理念为传统的工具理性所束缚,高校为了追求短期利益最大化,只能通过成本最低、最容易实现的方式对舆情进行“封、堵、删”,通过消磨公共的关注度来被动降温
主体碎片化:从高校外部治理主体之间的关系来看,高校舆情治理要服从于教育主管行政部门的领导,从横向来看,高校在舆情治理中与政府、媒体、专家和公众之间的沟通与合作并不紧密,形成各自管理、宣传的模式,导致高校舆情治理力量分散。
信息资源碎片化:一个是信息资源不集中,不同部门有着不同的信息资源,并且与政府或媒体之间缺乏有效衔接;一个是信息资源脱节,各级学院和学校也存在信息不一致的现象;还有一个是缺乏系统、整体的制度资源。
整体性路径思考:
树立公共意识和责任意识的高校舆情整体性治理的价值理念
构建以协调和整合为核心的高校舆情整体性治理机制
构建高校整体性治理的协调机制,强化、塑造各部门共同目标,建立跨部门、跨层级、跨组织的信息共享机制,人员专业化
构建高校整体性治理的整合机制,积极推进高校舆情治理的层级整合,促进高校舆情治理功能整合,加强与外界新媒体的沟通协作,不仅要掌握新媒体公关的技巧以及策略,与网络媒体建立互通互信的沟通渠道,还要主动邀请校外网络媒体帮助学校加强正面宣传
建立以高校为主的沟通系统:积极引导舆论,畅通公众与高校沟通渠道,并依法治理
文献一:
Jiawen Yan, Yuantao You, Yu Wang, Dongfang Sheng, “Understanding the Complexity of Business Information Dissemination in Social Media: A Meta-Analysis of Empirical Evidence from China”, Complexity, vol. 2021, Article ID 7647718, 13 pages, 2021. https://doi.org/10.1155/2021/7647718
虽然是一篇英文文献,但是是山东大学一位老师写的,主要内容就是通过Meta-Analysis(不知道元分析这个翻译对不对)对文献进行综合。对于元分析和文献综述的区别系统综述,Meta 分析:二次研究基础知识汇总,我在网上找到的区别是这么说的:
综述通常就给定领域或主题,提供现有知识的概述。撰写描述性综述的目的在于:总结现有知识,突出该领域的新观点,或提出亟待解决的问题。
系统综述更加详尽、严谨,并且针对确定的研究问题,而不是像描述性综述那样,涵盖一个领域或主题。系统综述使用系统性的、可重复的方法,搜索所有针对同一问题的已发表文献,并以综述的形式对这些已发表的结果进行严格评估和分析。可以是定性或者定量。
Meta 分析也是一种系统综述,但会额外进行统计分析,比较之前发表的研究结果,得出新的解读或发现。这些对于理解特定发现的总体效果非常有帮助,使研究者不必依赖于特定区域的单个孤立研究的结果。在那些已经有大量个案研究和小型研究的领域,Meta 分析非常受欢迎。
摘要:
基于Meta-Analysis,从个体行为的角度综合了20项实证研究,从信息来源可靠性、感知信息质量、舆情事件热度三个方面建立用户信息采纳模型的影响因素,结果表明,舆情传播的主要影响因素是权威性、可靠性、信息形式质量、信息编辑质量、信息效用质量和活动出席偏好。其中,信息编辑的权威性和质量对舆论传播中用户信息采纳行为的影响更为显着。此外,事件类型是否为公共紧急事件具有调节作用。
简介:
目标:
在现有相关文献的基础上,提出舆论传播中用户信息采纳行为影响因素的相关假设,通过元分析定量结合独立研究结果,进而对假设进行定性检验。
通过定量元分析检查已发表研究结果的趋同或分歧,并尝试用大样本和普遍适应性分析和解释有争议的结论。从定量研究的角度探讨影响网络舆情传播普遍性的因素,发现舆情信息的社会经济价值,为政府和企业调整优化风险提供有价值的理论参考和实践参考。舆论信息管理模式。
探索可能影响研究结果的调节变量,为未来的研究提供新的见解。
理论背景和假设
如何定义信息采用:定义较为分散,文章认为现实变量包括点赞评论转发等。
详尽可能性模型(Elaboration Likelihood Model):解释信息采纳一项最具代表性的模型。假设接收者在处理说服性诉求时存在“精细加工”的可能区间,信息处理和态度的基本维度之一是信息处理的深度和数量。在此模型下,人们在信息源的影响下改变态度和行为的过程用两条信息处理路径来描述,即中心路径和外围路径。中心路径是深思熟虑后的行为改变,而外围路径是未思考就改变行为的过程。
模型假设:
信息源可靠性对于用户信息采用行为的影响。可靠性是指信息接收者对信息源的信任程度,权威性是指受众感知的信息发布者的可信程度。
H1:信息源的权威与用户的信息采纳行为正相关
H2:信息源的可靠性与用户的信息采纳行为正相关
感知信息质量对用户信息采纳行为的影响。信息质量分类:信息形式质量、信息编辑质量和信息效用质量。
H3:信息形式质量与用户信息采纳行为正相关
H4:信息编辑质量与用户信息采纳行为正相关
H5:信息效用质量与用户信息采纳行为正相关
舆情事件热度对用户信息采用行为的影响,热度分为事件关注偏好和信息环境热度两个维度
H6:事件关注偏好与用户信息采纳行为正相关
H7:信息环境热度与用户信息采纳行为正相关
舆情事件类型的调节作用:目前普遍缺乏关于舆情事件类型对用户信息采纳影响的研究,提出探索性问题:舆情事件的类型(是否为突发公共事件)对舆情信息的采纳是否有影响?
方法
Meta-Analysis:对同一问题的多项独立研究的结果进行重新分析,通过整合这些独立研究的结果,形成一致的结论。
搜索策略:一个是收录主题和关键词为“舆论传播”的期刊文章和博士论文,及其参考书目;其次是在搜索和选择过程中的关键词是“舆论传播”、“舆论传播”和“信息采纳”。
进一步对研究文献进行筛选的原则:
如果这些研究涉及对用户在舆论传播中的信息采用行为的实证研究,则被选中。
为确保每项研究的独立性,如果在不同文章、会议论文和学位论文中报告的两项或多项研究基于确切的数据集,则将它们视为一项研究,仅选择一篇文章
如果用户的信息采用行为是研究的因变量,则被选中
如果研究报告了影响因素和样本量之间的相关性或相关系数和p值或t值和样本量之间的相关性,则选中研究,这些可以转换为相关性
我们排除了描述不明确和变量设计不合理的研究
数据变化:在确定好搜索策略后得到了1628篇文献,而最终筛选后得到了20篇!!!!!!9篇期刊文献11篇硕博论文!这个排除率也太大了。
编码:分为七个维度:代码编号、作者、文献来源(硕博论文、基金项目、期刊名称等)、变量数量、样本量、效应量和事件类型(是否为公共突发事件)
变量设计:与之前假设中的变量一致,并且将其具体划分为周边路线还是中央路线:
中央路线:感知信息质量,即信息格式、信息编辑质量、信息效用
周边路线:信息来源可靠性(权威和可靠)和舆论事件的热度(时间关注度和信息环境热度)
Meta-Analysis分析步骤:用的是Comprehensive Meta-Analysis软件(查了查价格,一年好几百美刀,不知道用盗版软件写论文会不会被告。)
我们使用原始文献中的相关系数作为效应量。对于其他文献,我们从样本中提取了t值和个体总数(N) 来确定最终效果大小。
我们采用固定效应模型或随机效应模型来评价舆情传播行为影响因素与用户信息采纳行为的相关系数。
我们计算了置信区间。显著相关是指置信区间不包括0。
我们使用Egger’s方法评估纳入文献是否存在出版偏差(查阅了一些电子书和Meta分析相关的论文,才知道这两个词的含义)
Egger方法,常用来生成漏斗图,用来评估是否存在publication bias
Publication Bias:当一项研究发表的可能性受到其结果的影响时,就会存在发表偏差。
最后,为了确定是否存在调节者(是否为公共事件),我们使用了 75% 规则,该规则认为,在考虑所有统计假象后,如果仍然存在 25% 的方差或观察到的效应大小,则调节者必须存在。
结果
异质性检验,异质性指组之间的组间差异,组间方差占总方差的比例越大,研究之间的异质性就越大,有参考文献使用Q检验(查了查还有点繁琐,具体原理明白了但是论文中的检测结果还没看懂)来确定纳入的文献是否同质。p<0.05时,研究中存在异质性,存在异质性采用随机效应模型,如果固定效应模型和随机效应模型得到的结果一致,则研究结果是同质的。
主要结果:H1-6得到验证,H7(信息环境热度)不成立
调节器分析:事件类型为公共紧急情况时的点估计值大于事件类型不是公共紧急情况时的点估计值。因此,我们可以推断事件类型在舆论传播中对用户的信息采纳行为具有调节作用。当事件类型为突发公共事件时,该变量在舆论传播中对用户信息采纳行为的影响较大。
Publication Bias:由于参数不足,H6 无法完成 Egger 测试,其他假设的p值均大于0.05,表明差异不显着。本研究不存在发表偏倚,meta分析结果未因发表偏倚而偏离真实结果。
结论与讨论
针对不同假设叙述不同内容,即xxx对用户信息采用行为的影响存在/不存在显著相关性。
另外:
其实我比较想看的是如何处理数据的那一部分,但是这篇文章只是草草提了一下使用的软件和前期的准备,然后就直接出结果了。难道这个软件的用法很普遍吗??
补充:查了查Meta分析,发现国内的文献中,运用这种分析方法的文献大部分是医学类的(近三年的发文量在年均1200左右),在【曾宪涛,冷卫东,郭毅,刘菊英.Meta分析系列之一:Meta分析的类型[J].中国循证心血管医学杂志,2012,4(01):3-5.】中作者提到了Meta分析的大致分类,包括单组、多组、累计分析、回归分析等,不过由于期刊是医学类期刊,所以分类里举得例子也都是医学里的,稍微有点晦涩。后来也是相同作者的另一篇文章讲了元分析中的软件:【曾宪涛,Joey S.W.Kwong,田国祥,董圣杰.Meta分析系列之二:Meta分析的软件[J].中国循证心血管医学杂志,2012,4(02):89-91.】,作者对不同的元分析软件进行了不同功能的比较,CMA软件算是功能性和易用性平衡最好的软件了,但是具体的使用过程就需要对整个Meta分析有个全面的了解。
文献二
Zhang N, Guo X, Zhang L, et al. How to repair public trust effectively: Research on enterprise online public opinion crisis response[J]. Electronic Commerce Research and Applications, 2021, 49: 101077. https://doi.org/10.1016/j.elerap.2021.101077
这一篇是在谷歌学术上搜到的,主旨是如何有效修复公信力:企业网络舆情危机应对研究。
概述:
通过5个汽车质量缺陷案例将文本挖掘与实证检验相结合,衡量不同信任修复策略在不同危机阶段的有效性,探索信任修复策略的效果机制和最优组合。
文献回顾
面对舆论危机,企业通常会发布公告来应对,大多数文献采用的是问卷调查法或者基于场景的实验提出信任修复策略,很少有研讨企业在网络舆论危机下信任修复策略的有效性,文章将文本挖掘与实证测试相结合,围绕两个问题展开:
质量缺陷危机中的企业能否通过响应公告有效修复公众信任?
企业采取什么样的信任修复策略最有效应对质量缺陷危机?
文章选取了5起汽车行业质量缺陷事件引发的网络舆情危机作为研究案例,从新浪微博收集13条企业回应公告和46896条网络评论,运用危机生命周期理论,对每个质量缺陷事件的生命周期进行划分,通过对企业响应公告的内容分析来区分各种信任修复策略,并进行情感分析关于网上评论。最后,构建有效性测试模型,测试信任修复策略的有效性以及不同信任修复策略在网络舆情危机各个阶段的有效性差异。
贡献:
从舆论动态演化的角度,探索修复措施的作用机制和优化组合(在哪些时期使用哪些措施最为有效)
假设
H1:在网络舆论危机中,企业采取的情感、信息和功能修复策略比无响应策略更能有效修复公众信任。
H2a:在网络舆论危机的急性期,企业采取的情感修复策略比信息修复策略和功能修复策略更能有效修复公众信任。
H2b:在网络舆论危机的慢性阶段,企业采取的信息修复策略比情感修复策略和功能修复策略更能有效修复公众信任。
H2c:在网络舆情危机的终止阶段,企业采取的功能修复策略比情感修复策略和信息修复策略更能有效修复公众信任。
研究方法

包括数据采集及处理、数据分析和有效性检测三部分:
先在微博进行数据采集,并划分不同的生命周期,然后使用”内容分析方法”(content analysis method)对不同的公告进行编码以得到不同危机阶段的信任修复策略类型,之后以情感分析方法计算情感强度。在有效性测试阶段将情绪强度转化为能够代表信任修复策略有效性的指标验证假设。
内容分析方法:
对收集到的数据进行定性或定量分析,与之对应有不同的编码方案。本文采用的是先对四种信任修复策略进行不同的编码,情感修复策略(A)、信息修复策略(B)、功能修复策略(C)和无响应策略( O),然后招募学生对企业的公告进行信息标注。得到不同事件中的不同企业的不同策略
情感分析:
情感分析部分作者用了”扩充的情感词典“来判断情感强度,在大连理工大学的中文情感词汇本体数据库的基础上以人工标注的方法对汽车领域的情感词汇进行扩充并确定情感词的权重系数。
(这里作者提到了一个用于检验不同人员标注结果一致性的指标:Cohen’s kappa系数,我查了一下,Kappa系数是用来检验不同人员对同一样本评估结果的一致程度的,包括Cohen’s kappa 和 Fleiss’s kappa,二者的区别是前者的检验员是特意选择且保持固定的,而后者的则是在一组可用的检验员中随机选择的。 ,一般当结果在0.75以上时表示一致性强。)
,一般当结果在0.75以上时表示一致性强。)
在计算情感强度的时候作者使用的方法也很巧妙:
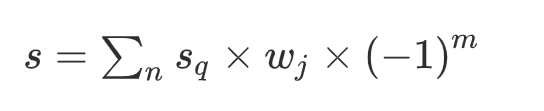
对每条微博进行拆分,然后sq表示每个情感词的情感强度值(情感词典中给出了),wj表示程度副词的权重,m代表否定词的个数,偶数次幂为正,奇数次幂为负。
有效性测试:
作者引用了一些论文说明很多人是直接用情绪代表信任程度,所以作者也用了用样的方法,而如何计算这一节的情绪也是一个复杂的步骤。他们认为此类事件的情绪会受到前一个阶段和当前阶段的策略的共同影响,所以设置当前的综合情绪强度为上一个阶段的情绪强度与当前情绪强度的和。
在情感计算中,作者提到【在上一个危机阶段,无法准确获取与危机阶段一一对应的每一条微博评论的情感强度,所以使用上一个危机阶段的情感均值来加和】,这句话困扰了我好久,终于想明白了:
首先,每条微博的情感强度计算公式是:
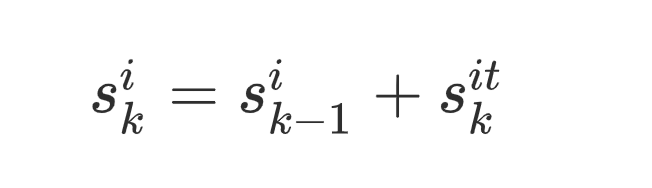
Ski表示综合的情感强度,k-1则是上一个危机阶段的情绪强度,Sitk是在i事件下的k阶段的情绪强度。每条微博的当前阶段是可以确定的,但是这个微博用户在上一阶段不一定发表过评论,所以无法确定每条微博都有上一阶段的情感强度,而每一阶段的微博是可控的,所以作者就用了上一阶段的所有微博的情感强度均值来代替某一微博的上一阶段的情感强度。
而信任修复策略的有效性应该是检验不同阶段的情绪强度,所以,Sitk是最终指标,计算方法就可以用综合情感强度减去上一阶段的情感均值
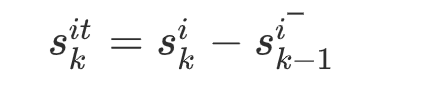
但是我不理解的是,直接计算当前阶段的情感均值不行吗?为什么还绕这么多弯?还是说我还没理解对?
假设检验
检验过程就是检验每个事件中采取的不同策略的有效性变化,包括平均值、方差和极值
并且作者还对混合策略以及单一策略进行了有效性测试。
讨论与结论
一、企业在网络舆情危机各阶段采取的信任修复策略都是有效的,能够显着缓解舆情,有效修复公众信任。结果也印证了相关场景实验的结论,即企业在情感、信息和功能上的努力,有利于重塑诚信形象,赢得公众信任
二、在网络舆论危机的不同阶段,不同信任修复策略的效果是不同的:(1)在网络舆论危机的急性期,情感修复策略最有效;(2)在慢性期,信息修复策略最为有效;(3)在终止阶段,功能修复策略是最有效的。从而验证了文章提出的信任修复策略的作用机制,揭示了信任修复策略的最优组合。
另外:
我发现时间都花在了找文献上了,找论文能找两个小时,看也就个数小时看完了,搜英文文献的时候总是抓不住能出结果的关键词,比如我想搜舆论和企业这两个主体,在谷歌学术和webOfScience上通常就是搜(Public opinion) AND ((company) or (enterprise)),这样能搜出好多文章,但是如果再细化到像company technology或者enterprise profit这种,搜出的论文就很少而且贴合程度也不高。
另外一个,可能对于这个英文的写作也是不熟悉,每次在Google 和webofscience上搜的时候,搜出来的一些比较贴合题意的文章都是国内学者写的英文文献。不过好处就是不会有太多晦涩难懂的地方,顶多是专业词汇。而且“英文文献”这个属性的好处就是作者都会写的十分详细,每篇文章中需要自己额外查的东西相对会比较少。